索引优化
性能优化思路
选择合理范围内最小的
选择最小的数据范围,因为这样可以大大减少磁盘空间及磁盘 I/0 读写开销,减少内存占用,减少 CPU 的占用率
选择相对简单的数据类型
数字类型相对字符串类型要简单的多,尤其是在比较运算中,应该选择最简单的数据类型,比如说在保存时间时,我们可以将日期存为
int(10),这样会更方便、合适、快速的多
字符串类型的优化思路
字符串数据类型是一个万能数据类型,可以储存数值、字符串等
- 保存数值类型最好不要用字符串数据类型,这样存储的空间显然是会更大,同时,如果进行运算时
mysql会将字符串转换为数值类型,这种转换是不会走索引的 - 如果明确数据在一个完整的集合中如男,女,可以使用
set或enum数据类型,这种数据类型在运算及储存时以数值方式操作,所以效率要比字符串更好,同时空间占用更少
数值类型的优化思路
整数
整数类型很多比如 tinyint、int、smallint、bigint 等,我们要根据自己需要存储的数据长度决定使用的类型,同时 tinyint(10)与 tinyint(100)在储存与计算上并无任何差别,区别只是在显示层面上,但是我们也要选择适合合适的数据类型长度。可以通过指定 zerofill 属性查看显示时区别
浮点数与精度数值
浮点数float 与double在储存空间及运行效率上要优于精度数值类型 decimal,但 float 与 double会有舍入错误,而 decimal 则可以提供更加准确的小数级精确运算不会有错误产生计算更精确,更适用于金融类型数据的存储
EXPLAIN
EXPLAIN 指令可以帮助开发人员分析 SQL 问题,explain 显示了 mysql 如何使用索引来处理 select语句以及连接表,可以帮助选择更好的索引和写出更优化的查询语句
通过EXPLAIN进行查询,返回的查询结果字段介绍(从左到右依次进行介绍):
| 字段 | 说明 |
|---|---|
id | 索引执行顺序 |
select_type | 查询类型 |
table | 操作表 |
type | 使用类型 |
possible_keys | 可能用到的索引,不一定被真正使用 |
key | 最终使用的索引 |
key_len | 索引字节数 |
ref | 列与索引的比较 |
rows | 预计读出的记录条数 |
Extra | 查询说明 |
对于使用类型
type,有下面常见的值:
const:使用主键值比较,匹配唯一行检索,速度快sqlexplain select * from stu where id = 3;
ref: 前面表中的非唯一数据
eq_ref:前面表中非唯一数据,使用了唯一索引字段,如表关联时使用主键
range:索引区间获得,如使用IN(1,2,3)筛选sqlexplain select * from stu where class_id in(1,2,3);
all:全表遍历sqlexplain select * from stu where birthday = '20000213';
index:与all类似只是扫描所有表,而非数据表sqlexplain select * from stu order by id;
基础索引
合适的索引优化可以大幅度的提高Mysql的检索速度,索引就像书中的目录一样让我们更快的寻找到自己想要的数据,但是我们也不能过多的创建目录页(索引),原因是如果某一篇文章删除或修改将发变所有页码的顺序,就需要重新创建目录
索引优化是针对于海量数据的数据库,优化其数据的查找速度,增强其性能,减少开销(注意:创建索引后,只对创建了索引的列有提高查询速度的效果,如果换一个字段进行条件查询,是没有效果的)
索引机制:
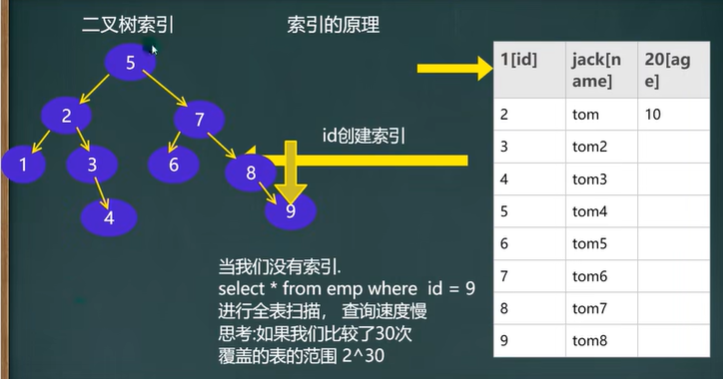
我们将
id设置了索引后,我们去查找id为9的具体内容,我们只需要查找4次就可以找到,比没有设置索引快很多
索引的弊端:
- 创建索引会使查询操作变得更加快速,但是会降低增加、删除、更新操作的速度,因为执行这些操作的同时会对索引文件进行重新排序或更新(二叉树的数据结构会改变,对修改、删除等操作的速度有影响)
- 创建过多列的索引会大大增加磁盘空间开销(索引本身也会占据空间)
- 不要盲目的创建索引,只为查询操作频繁的列创建索引
索引的使用经验:
- 较频繁的作为查询条件字符的列应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使使用频繁作为查询条件
- 更新非常频繁的字段不适合创建索引
- 不会出现在
WHERE子句中的字段不应该创建索引
索引类型
| 索引 | 说明 |
|---|---|
UNIQUE 唯一索引 | 不可以出现相同的值,可以有 NULL 值 |
INDEX 普通索引 | 允许出现相同的索引内容 |
PRIMARY KEY 主键索引 | 不允许出现相同的值,且不能为 NULL 值 |
FULLTEXT 全文索引 | 适用于MyISAM,一般用于搜索文章中的关键字,FULLTEXT的全文索引方式用的比较少,在开发中一般使用Solr和ElasticSearch |
选择规则:如果某列的值是不会重复的,则优先考虑使用unique索引,否则使用普通索引
索引维护
设置索引:
ALTER TABLE stu ADD INDEX sname_index(sname)为
stu学生表中的sname字段设置索引,sname_index为设置索引的别名我们也可以在创建字段的时候添加索引:
CREATE INDEX sname_index ON stu (sname)设置主键索引:
ALTER TABLE stu ADD PRIMARY KEY (id)删除索引:
ALTER TABLE stu DROP INDEX sname_index删除主键索引,首先需要移除
auto_increment(自增属性)然后删除主键索引:sqlALTER TABLE stu MODIFY id int; ALTER TABLE stu DROP PRIMARY KEY查看索引:
- 方式一:
SHOW INDEX FROM stu; - 方式二:
SHOW INDEXES FROM stu; - 方式三:
SHOW KEYS FROM stu;
- 方式一:
性能分析
索引是加快查询操作的重要手段,如果当发生查询过慢时,为这个字段添加上索引后,会发现速度大大改观
对于没有添加索引属性的字段进行查找,会执行全盘扫描,性能是最差的
sqlEXPLAIN SELECT * FROM stu WHERE class_id=5 LIMIT 1;查找
stu数据表中,class_id等于5的第一条数据结果显示
type=ALL看出执行了全表扫描,rows数量较多如果为
class_id字段添加索引,后再执行查找:sqlALTER TABLE stu ADD INDEX class_id(class_id); EXPLAIN SELECT * FROM stu WHERE class_id=5 LIMIT 1;从
type字段看出已经走了索引,本次查询遍历了少量的记录,rows数量较小
对于多表操作,连接操作多个表时,如果没有添加索引性能会非常差
对于没有使用索引的情况:
sqlexplain select * from a join b on a.id=b.id join c on b.id=c.id;从结果中会看到每张表都遍历了所有记录,其
type值都为ALL,遍历大量数据,性能较差为其都添加索引后的情况:
sqlALTER TABLE a ADD INDEX id(id); ALTER TABLE b ADD INDEX id(id); ALTER TABLE c ADD INDEX id(id); explain select * from a join b on a.id=b.id join c on b.id=c.id;执行的结果会看到使用了索引,并且并没有进行全表遍历
前缀和组合索引
前缀索引
text/长varchar 字段创建索引时,会造成索引列长度过长,从而生成过大的索引文件影响检索性能。使用前缀索引方式进行索引,可以有效解决这个问题。前缀索引应该控制在一个合适的点,控制在前百分之30即可
下面是取前缀索引的计算公式,有时也根据字段保存内容确定,比如标题 100 可以取 30 个字符为前缀索引:
select count(distinct(left(title,10)))/count(*) from news为文章表 article 的 title 字段添加 30 个长度的前缀索引:
ALTER TABLE article ADD INDEX title(title(30));组合索引
组合索引是为多个字段统一设计索引
- 可以较为每个字段设置索引文件体积更小
- 使用速度优于多个索引操作
- 前面字段没出现,只出现后面字段时不走索引
为学生表中的班级字段class_id与学生状态status设置组合索引:
Alter table stu add index class_id_status(class_id,status);使用
class_id时会走索引,因为class_id在组合索引最前面:sqlexplain select * from stu where class_id=3;查询结果
type为ref,表明走了索引,走的索引key为class_id只使用
status字段不会走索引:sqlexplain select * from stu where status=1;查询结果
type为ALL,表明进行了全盘查找当
class_id与status字段一起使用时会走索引:sqlexplain select * from stu where status=1 and class_id=5;查询结果
type为ref,表明走了索引,走的索引key为class_id_status
字段选择
维度思考
维度的最大值是数据列中不重复值出现的个数
如数据表中存在8行数据
a,b,c,d,a,b,c,d,则这个表的维度为 4
索引规则
- 对
where,on或group by及order by中出现的列(字段)使用索引 - 对较小的数据列使用索引,这样会使索引文件更小,同时内存中也可以装载更多的索引键
- 为较长的字符串使用前缀索引
- 要为维度高的列创建索引
- 性别这样的列不适合创建索引,因为维度过低
- 不要过多创建索引,除了增加额外的磁盘空间外,对于
DML操作的速度影响很大
查询优化
解析器
Mysql的解析器非常智能,会对发出的每条SQL进行分析,决定是否使用索引或是否进行全表扫描表达式影响
索引列参与了计算的
SQL语句不会使用索引:sqlexplain select * from stu where status+1=1;type为ALL索引列使用了函数运算的
SQL语句不会使用索引:sqlexplain select * from stu where left(sname,1)='金';type为ALL索引列使用模糊匹配的
SQL语句不会使用索引:sqlexplain select * from stu where sname like '%1%';type为ALL索引列使用正则表达式的
SQL语句不会使用索引:sqlexplain select * from stu where sname regexp '^1';type为ALL类型比较
相同类型比较时走索引:
sqlexplain select * from stu where sname="xiaojin";sname的类型为字符串类型,与之比较的内容类型也是字符串类型,因此走的索引字符串类型与数值比较时不走索引:
sqlexplain select * from stu where sname=1;type为ALL排序
排序中尽量使用添加索引的列进行
慢查询
当 Mysql 性能下降时,通过开启慢查询来了解哪条SQL语句造成响应过慢,后续可以进行分析处理。当然开启慢查询会带来 CPU 损耗与日志记录的 IO 开销,所以我们要间断性的打开慢查询日志来查看 Mysql运行状态
慢查询能记录下所有执行时间超过设定 long_query_time 时间的SQL语句, 用于找到执行慢的 SQL语句, 方便我们对这些 SQL语句进行优化
运行配置
会话配置
通过以下指令开启全局慢查询(重起Mysql后需要重新执行)
set global slow_query_log='ON';设置慢查询时间为 1 妙,即超过 1 秒将会被记录到慢查询日志
set session long_query_time=1;全局配置
通过修改配置 mysql 配置文件 my.cnf 来开启全局慢查询配置,在配置文件中修改以下内容
slow_query_log = ON
slow_query_log_file = /usr/local/mysql/data/slow.log
long_query_time = 1重起 MYSQL 服务
service mysqld restart状态查看
查看开启慢查询状态:show variables like 'slow_query%';
查看慢查询的设置时间:show variables like "long_query_time";