事务处理
事务用于保证数据的一致性,由一组相关的dml语句(修改、添加和删除语句)组成,该组的dml语句要么全部成功,要么全部失败
事务可以理解为mysql所做的事情,通过sql语句进行控制
有的简单事务通过一条sql语句就可以完成,该事务要么成功要么失败,但是有的复杂的事务,需要多条sql语句才能完成,如回复评论引发的其他内容的变化,这个是一条链的执行过程,如果在某个环节出现了问题,这个链就是缺损的,是不完整的。我们需要考虑,如果某个环节出现了问题,我们是否需要让这条链全部撤销掉重做?对于不同的情况,有不同的考虑方式,如回复评论引发的后续其他内容的变化,是不需要撤销重做的,我们可以不用保证每一块业务的完整性,因为后续更新的时候会保证修正操作,也就是说,某个环节的异常不会对整体产生严重影响,我们可以不需要进行撤销重做,可以进行宽松对待;对于要求比较严格的,如商城系统、库存系统等实时交易,我们必须要求该事务是一个整体,要么全部成功,要么全部失败。
事务的操作语句:
- 开启一个事务:
start transaction - 设置保存点:
savepoint 保存点名 - 回退事务:
rollback to 保存点名 - 回退全部事务(回退到事务开始的状态):
rollback - 提交事务,所有的操作生效,不能再回退:
commit
保存点是事务中的点,用于取消部分事务,当事务结束时(即提交了事务),会自动的删除该事务中所定义的所有保存点,当执行回退事务时,通过指定的保存点可以回退到指定的点
提交事务,使用commit语句可以进行事务的提交,当执行了该语句后,会确认事务的变化、结束事务、删除保存点、释放锁、数据生效。当使用commit语句结束事务后,其他会话可以查看到事务变化后的新数据
注意事项:
- 如果不开启事务,在默认情况下,
dml操作是自动提交的,不能进行回滚 - 如果开始一个事务,但是没有创建保存点,后续可以执行回滚操作,但是只能回滚到一开始开启事务的状态
- 可以在事务没有提交之前,选择回退到哪个保存点
mysql的事务机制需要innodb的存储引擎
事务存储引擎的选择
存储引擎的基本介绍:
mysql的表类型由存储引擎决定,主要包括MyISAM、innoDB(默认的引擎)、Memory等mysql数据表主要支持六种类型,分别是CSV、Memory、ARCHIVE、MRG_MYISAM、MYISAM、InnoBDB六种类型又分为两类,一类是”事务安全型“,如
InnoBDB,其余的都属于第二类,”非事务安全型“
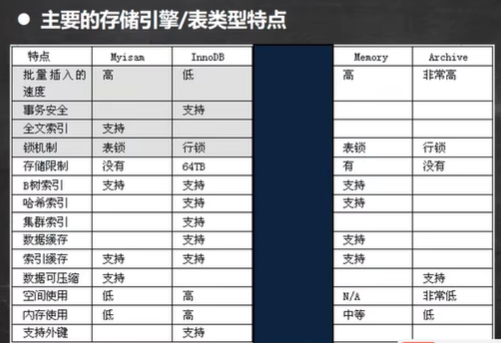
常用引擎的主要区别: 
事务的方式是受存储引擎影响的
我们可以通过SHOW engines;来查看mysql支持的存储引擎,其中innoDB是默认的存储引擎,是支持事务处理的,如果有一些老的数据表,使用的是其他的存储引擎,我们可以进行存储引擎的修改:
ALTER TABLE stu engine = 'InnoDB';也可以使用图形化界面进行修改
事务单独开启
开启事务将后续的sql语句归类为一组进行执行,要么全部成功,要么全部失败,不会出现某条sql语句执行成功,具体的开启事务的方式为:
BEGIN;
INSERT INTO class(canme)VALUES('研究生');
COMMIT;
ROLLBACK;执行
BEGIN;语句后,后面输入执行的sql语句就是一组在一个用户在执行事务的时候,成功执行了一条语句后,当前
mysql用户是可以看到具体结果的,但是另一个用户是查询不到该执行结果的,因为mysql认为第一个用户的事务还没有完成,可能还有其他的sql语句,如果想要结束,需要使用COMMIT;进行事务的提交,提交完后,这条数据才会真正的写入硬盘的数据表当中,其他用户就可以查询到事务中新增的数据了。简而言之,
BEGIN;语句将多条事务连接成一组了;COMMIT;语句将多条语句进行统一的执行了除了
BEGIN;,还有其他的开启事务的语法:START TRANSACTION;如果在执行
sql语句的时候,有一条语句出现了问题,我们可以进行回滚操作ROLLBACK;,回滚可以理解为放弃上一条执行的sql语句(撤销上一条sql语句的执行),如果出现异常,我们可以使用ROLLBACK;,让其进行回滚,但是要注意,当执行ROLLBACK;后,和COMMIT;一样,这个事务就走完了,后续还是回到默认的方式,即执行一条sql语句,生效一次
全局的事务开启
每执行一个事务,我们都需要进行开启事务,如果要求全部的sql语句必须要全部使用事务的方式,我们可以开启全局事务,不用每一次提交后,再重新开启事务,全局事务开启的设置:
SET autocommit = 0; # 或者SET autocommit = off;
INSERT INTO class(canme)VALUES('研究生');
COMMIT;表示执行
sql语句的时候,系统不会自动的进行提交,必须进行COMMIT;操作才可以进行提交,将真正的数据写入到硬盘上,其他用户才能看到,否则,只是当前执行sql语句的用户能看到
事务隔离级别与脏读
在高并发的状态下,可能会有多个事务在同时操作一张数据表,这个时候可能就会出现脏读和幻读等问题
- 脏读:事务A读取了事务B更新的数据,然后B进行了回滚操作,那么A读取到的数据是脏数据
- 不可重复读:事务A多次读取同一数据,事务B在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时(这个时候事务A还没有进行提交,按理说是看不到事务B提交的内容的),结果不一致
- 幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A结束后发现还有一条新的记录也被改过来了,就好像发生了幻觉一样
我们希望每个事务之间是独立的,不同的事务不会互相干扰,这就需要引入事务隔离操作,事务隔离有不同的隔离级别,但是,隔离级别越好,会导致性能变差,因此设置隔离级别的时候也要兼顾性能
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 | 说明 |
|---|---|---|---|---|
读未提交(read-uncommitted) | 是 | 是 | 是 | 最低的事务隔离级别,一个事务还没提交时,它做的变更就能被别的事务看到 |
不可重复读(read-committed) | 否 | 是 | 是 | 保证一个事物提交后才能被另外一个事务读取。另外一个事务不能读取该事物未提交的数据 |
可重复读(repeatable-read) | 否 | 否 | 是 | 多次读取同一范围的数据会返回第一次查询的快照,即使其他事务对该数据做了更新修改。事务在执行期间看到的数据前后必须是一致的 |
串行化(serializable) | 否 | 否 | 否 | 事务 100% 隔离,可避免脏读、不可重复读、幻读的发生。花费最高代价但最可靠的事务隔离级别 |
查询当前使用的事务隔离级别:select @@global.transaction_isolation,@@transaction_isolation;
默认情况下,mysql使用的事务隔离级别是repeatable-read
我们可以进行事务隔离级别的设置:set session transaction isolation level read uncommitted;
设置事务隔离级别的时候,将级别名称的-去掉进行设置
使用串行化来阻止幻读的现象,会使用锁机制,将中间开启的事务进行锁定,当之前的事务结束时,中间开启的事务才会继续的自动往下执行,这样就防止出现幻读