数据表相关指令
创建表:
CREATE TABLE 数据表的名称 (id int PRIMARY KEY AUTO_INCREMENT, cname varchar(30) not null, description varchar(100) null) CHARACTER SET 字符集 COLLATE 校对规则 ENGINE 存储引擎;对于数据表创建时,如果数据表长度较长,推荐使用下划线进行分隔
上述创建的数据表有3个表字段,
id、cname和descriptionid是int数字类型;同时是一个主键(主键查找的速度比较快),通过PRIMARY KEY声明;AUTO_INCREMENT表示设置数据自增(随着数据条目的增加,id的值是自增的,保证id值的唯一性)主键在添加数据的时候我们一般不用管,它会自己进行维护,来一条数据自增一下(但是删除完对应的数据,id不会在后续继续使用,为了保证唯一性)varchar表示字符串类型的数据结构,30和100表示设置字符串的最大长度not null表示设置输入的内容不能为空(字段是必填项),null表示输入的内容可以为空AUTO_INCREMENT自增长的使用细节:- 一般来说,自增长是和主键进行配合使用的
- 自增长也可以单独使用,但是要配合
unique - 自增长修饰的字段一般为整数型
- 自增长默认从1开始,也可以通过命令去修改初始值:
ALTER TABLE 表名 AUTO_INCREMENT = 新的开始值; - 如果添加数据时,给自增长字段(列)指定值,则以指定的值为准,如果没有指定值,或者指定的为
null,那么设置自增长约束的字段就会根据之前的值进行自增长填入
对于字符集和校对规则,我们可以不进行指定,这样的话创建的数据表就会继承所在数据库的字符集和校对规则
查看当前数据库中的表:
DESC 数据表的名称
删除表:
DROP TABLE if EXISTS 数据表的名称if EXISTS这条语句建议加上,如果数据表不存在时,有这条语句后台是不会报错的
为数据表添加数据,通过命令行进行为数据表插入数据
插入一条数据:
INSERT INTO 数据库的名称 set cname = 'mysql', description = '学习mysql数据库';插入多条数据:
INSERT INTO class (cname, description) VALUES('Linux', '服务器知识'), ('git', null);
插入语句的注意事项:
插入的数据应与对应字段的数据类型相同
但是对于字符串
'30',mysql的底层会尝试着将其转化成int数据的长度应该在列的规定范围内(长度不能溢出数据类型设置的范围)
在
valuse中列出的数据位置必须与被加入的列的排列位置相对应字符和日期数据应该使用单引号来包裹
列可以插入空值
NULL(前提是该字符允许为空,在创建表示对字符不做约束,则默认时可以为空的,如果设置了NOT NULL,则表示该字段的值不能为空)如果是给表中的所有字段添加数据,可以不写前面的字段名称
当不给某个字段添值时,如果有设置了默认值就可以正常添加,否则报错
当然,我们也可以直接在图形化界面中为数据表插入一条数据,在单元格中输入数据,最后点击保存
根据其他表来快速的生成一张表
首先要创建一张表,同时说明这个新表的表结构来源于哪张旧表
create table 创建的新数据表名称 like 旧数据表的名称;like可以理解于数据结构来源于哪张旧表,这样创建的新表会和旧表有着一样的数据表字段和类型有时我们想要在创建相同表结构的基础上还要将数据也复制过来,可以通过以下的方式:
insert into 创建的新数据表名称 select * from 旧数据表的名称;select表示查询操作;*表示所有字段;有时候我们可能不想要所有的字段,我们只想要其中一个字段的数据,可以将代码进行以下的修改:
insert into 创建的新数据表名称(cname) select cname from 旧数据表的名称;
表数据的自我复制:
INSERT INTO table1 SELECT * FROM table1;我们也可以将上述两个步骤合成一个,在创建的表的时候,使数据连同一起过来
CREATE TABLE 创建的新数据表名称 select * from 旧数据表的名称;也可以创建新表的时候拿一部分字段的数据:
CREATE TABLE 创建的新数据表名称 (id int PRIMARY KEY AUTO_INCREMENT, cname varchar(30)) select cname from 旧数据表的名称;当我们新表的字段名称和旧数据表的名称不同时,我们需要进行如下的修改:
CREATE TABLE 创建的新数据表名称 (id int PRIMARY KEY AUTO_INCREMENT, name varchar(30)) select cname as name from 旧数据表的名称;
查询表
查询表通过SELECT方式进行查询,具体的方式如下所示:
SELECT DISTINCT * FROM 要查询的数据表;DISTINCT是一个可选项,指在显示结果时,是否去掉重复的数据(每个字段的值都相同,才算是相同项)*表示查询所有的字段根据需要查询数据表中指定的字段:
SELECT cname, id FROM 要查询的数据表;最后查询的结果返回也是根据查询时输入的字段顺序进行返回的(
cname这一列字段在id这一列字段前面),有时候在多表关联的查询的时候,会出现同名的字段,这个时候就需要进行别名的设置:SELECT cname, id as ids FROM 要查询的数据表;这时查询返回的字段名就是
cname和ids我们在实际查询操作的时候,往往是不会把一张表的所有数据都进行查询的(可能数据表的数据非常大,都拿出来不现实),我们一般使用基于条件的筛选查询(结果返回的是符合这个筛选条件的所有数据条目):
根据某个字段的数值大小进行筛选:
SELECT * FROM 数据表的名称 WHERE id > 2;根据某个字段的内容进行查询筛选:
SELECT * FROM 数据表的名称 WHERE cname = 'mysql';查找字段中包含某个元素的内容:
SELECT * FROM 数据表的名称 WHERE description like '%l%';但是在实际应用中,
like的搜索性能会有一定的差异,我们一般使用一些第三方的搜索,包括使用一些云主机的搜索,这些的搜索功能比较强悍
上述的筛选条件进行组合在一起进行查找筛选,找到同时满足条件的数据:
SELECT * FROM 数据表的名称 WHERE description not like '%l%' and id > 2;not表示非;and表示与;or表示或%l%表示查找任何位置出现内容l;%l表示查找以l结尾的内容;l%表示查找以l开始的内容_l%表示查找第二个字符内容为l的记录_的作用范围是一个字符;%的作用范围是多个字符在有的时候,我们需要将多个列的结果进行合并返回,我们可以使用连接函数进行连接:
SELECT CONCAT(cname, description) as class_info from 数据表的名称;一般情况下,我们需要为其起别名,不然返回的字段是这整个连接函数的内容,会过于长了
查询的时候,进行统计运算:
SELECT name, (chinese+english+math) AS total_score FROM stu;
关键字查询
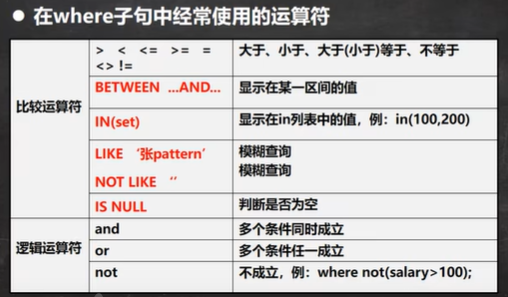
关键字查询中的关键字包括:between,like,in等等
在此基础上我们先新建另一个班级数据表:
CREATE TABLE stu (id int PRIMARY key AUTO_INCREMENT, sname char(10), class_id int DEFAULT null, age SMALLINT not null);
在新建的学生表中插入一些基本的数据:
INSERT INTO stu(sname, class_id, age) VALUES('小明', 1, 22), ('小红', 2, 23), ('小亮', 2, 24), ('小白', null, 22);
查找哪些班级有学生:
SELECT DISTINCT class_id FROM stu;DISTINCT的作用是去重,返回有学生的班级,班级不应该重复出现查找年龄在18到23之间的数据,有以下的两种写法:
SELECT * FROM stu WHERE age >= 18 AND age <= 23;SELECT * FROM stu WHERE age BETWEEN 18 AND 23;(BERWEEN.AND是两边闭区间)查询学生班级在1班或者2班的数据,有以下的两种写法:
SELECT * FROM stu WHERE class_id = 1 OR class_id = 2;SELECT * FROM stu WHERE class_id in(1, 2);
Mysql对NULL的处理技巧
空不能和任何的值相比较,如stu数据表单,我们通过SELECT * FROM stu WHERE class_id = null;是查询不到内容的(虽然在插入语句中有一条数据的class_id的内容为null)
针对这个问题,Mysql提供了相应的关键字:SELECT * FROM stu WHERE class_id is null;这样我们就可以查询到('小白', null, 22)这条记录
小案例:对于查询stu表的所有数据,如果有班级就显示班级的编号,如果班级字段的内容为null,就显示班级未分配:
-- 方式一
SELECT sname, if(class_id, class_id, '未分配'),age from stu;
-- 方式二
SELECT sname, ifnull(class_id, '未分配'), age from stu;排序操作
我们可以对数据表中的某个字段进行排序操作:
对stu数据表中的年龄字段进行从大到小进行排序:SELECT sname, age FROM stu order by age desc;
对于排序:
desc表示降序(从大到小);asc表示升序(从小到大)
null表示最小,如果升序排序,会出现在最前面
小案例:对于班级进行升序排序,如果班级相同则通过年龄进行升序排序:
SELECT * FROM stu order by class_id asc, age asc;排序可以指定多个字段
同时对于返回的数据条目,我们可以指定个数进行展示,下面例子表示取输入的最后一条数据(先进行降序排序,在进行
limit取选取一条数据)
SELECT * FROM stu order by class_id asc limit 1;也可以用如下的方式进行写:
SELECT * FROM stu order by class_id asc limit 0,1;
limit也可以接收两个参数,第一个表示从哪一个开始,第二个表示取几条数据,如limit 0, 2表示取第一条和第二条数据(从第一条数据开始取,取两个)
LIMIT 每页显示记录数 * (第几页 - 1), 每页显示记录数
更新表数据
我们更新表数据一般使用UPDATE关键字,更新一般是需要加上条件的,不然就会将这张表中要更新的字段内容全部修改了
将
stu数据表中class_id为空的字段设置为class_id为2:UPDATE stu SET class_id = 2 WHERE class_id is NULL;如果没有加
WHERE,会修改该字段的所有记录将年龄小于22岁的人员班级设置为班级1:
UPDATE stu SET class_id = 1 WHERE age < 22;
注意事项:
UPDATE语句可以用新值更新原有表行中的各列SET子句指示要修改哪些列和要设置哪些值WHERE子句指定应更新哪些行,如果没有该子句,则更新所有行
删除表数据
我们删除表中的数据一般使用DELETE关键字,删除条目一般也是需要加上条件的
- 删除班级为
null的这条数据:DELETE FROM stu WHERE class_id is NULL; - 删除最后报名的两个学生:
DELETE FROM stu order by id desc limit 2; - 将表中的所有记录都删除:
DELETE * FROM stu;
删除数据是对行进行操作的(整条数据),不能对某一列进行删除操作(只能使用UPDATE将某一列的值设置为null或者'')
修改数据表的结构
修改数据表的结构是一个相对低频的操作,一般在确定表后,都很少进行其结构的修改,但是也需要了解一下表结构修改的SQL语句
修改数据表的名称,将数据表
stu的名字修改为stus,有以下的两种方式:ALTER TABLE stu RENAME stus;RENAME TABLE stu TO stus;
创建一个备份表,将一张数据表进行备份:
CREATE TABLE stu_bak SELECT * FROM stu;修改数据表的字符集:字符集一般是在创建表的时候确定的,后续不会轻易修改的,但也可以修改:
ALTER TABLE stu charset gbk;将字符集改为gbk的形式清空表数据:
DELETE FROM stu;将stu表的数据全部清空,有些数据库管理软件会进行二级确认,这样的删除方式是一条一条进行删除,删除的速度是比较慢的,如果想要快速的进行清空表中的数据,可以使用:TRUNCATE stu;
表字段的维护
有时候我们可能需要对数据表中字段进行维护操作,如修改表字段的名称、类型等等
修改表字段名称,同时修改数据类型和设置必填:
ALTER Table stu CHANGE sname name varchar(50) not null;修改数据类型和是否必填:
ALTER Table stu MODIFY sname varchar(50) not null;添加一个新的字段(列):
ALTER Table stu ADD sex smallint default null;添加一个新的性别字段,字段名称为
sex,字段类型为smallint,字段的默认值为null可以在添加语句的最后加上要添加的字段在哪个字段的后面
AFTER name(在name字段的后面添加新的字段)想让指定字段在某个位置进行存放,创建一个新字段,并且使这个新字段在
id字段的后面:ALTER Table stu ADD email varchar(50) default null AFTER id;让一个新字段出现在所有字段的最前面:
ALTER Table stu ADD qq varchar(50) default null first;删除字段:
ALTER Table stu Drop sex;删除sex字段
对表中主键的维护
对表中主键的维护是一个非常低频的操作
删除主键:对于自增的主键是没有办法进行直接删除的,我们需要将其自增的属性先修改掉,再删除主键
- 将主键自增的属性去掉:
ALTER table stu MODIFY id int not null; - 再进行主键的删除:
ALTER table stu drop PRIMARY key;
上述两个操作执行完,
id的主键属性是消失了,但是id这个字段还是存在的,变成了一个普通的字段- 将主键自增的属性去掉:
添加主键:为上述删除主键的
id重新添加回主键:ALTER table stu add PRIMARY key (id);添加主键的自增属性:
ALTER table stu MODIFY id int not null AUTO_INCREMENT;添加主键和添加自增属性可以一起执行:
ALTER table stu modify id int not null AUTO_INCREMENT, add PRIMARY key (id);
数据表内容的去重
对于数据表中重复的内容进行去重,是一个非常经典的面试题,基本的思路如下:
先创建一张临时表
temp,该表的表结构和需要去重的表table一样sqlCREATE TABLE temp LIKE table;通过
DISTINCT关键字处理后,从表table中复制记录到temp表中sqlINSERT INTO temp SELECT DISTINCT * FROM table;清除掉
table表的记录sqlDELETE FROM table;把
temp临时表的记录复制到tablesqlINSERT INTO table SELECT DISTINCT * FROM temp;删除掉临时表
tempsqlDROP TABLE temp;